Crowd avoidance with data science

I love bouldering. But with social distancing guidelines in place (and bouldering gyms being the germ factories they are), it is best to hit the gym when its least busy. Plus, sometimes it’s just great to have the place (almost) to oneself.
Luckily, my local gym now has a neat little meter on its website (lecube.ch) that tells how busy it is at any given point in time and which helps avoid the very busy hours. Still, it would be even greater if there were a way to estimate how busy it is going to be over the next hours…
Enter time series forecasting. This is a set of methods used in data science and econometrics to predict how some real-world feature — say, quarterly sales of some product, stock prices, traffic,… — will likely develop in the future, given how it has developed in the past (see e.g. Hyndman & Athanasopoulos 2018). And these tools tend to work particularly well when there is strong regularity in the data: When traffic is predictably busiest between 7 and 9am and 5 and 7pm, and less so in the hours between or on weekends, for instance. From my experience, this is the case for bouldering gyms. They are typically less busy on Monday or Tuesday mornings and more so on, say, Friday evenings. So I thought let’s give this a try.
Step 1: Collecting data
My gym only provides current data on how busy it is, but not data from past timepoints. This meant I had to collect data from their website for some time first to have a dataset that I could use for forecasting.
I therefore wrote a little webscraper in R that calls their website at regular intervals (I set it to every full and half hour ), extracts the latest figure using the Xpath of the meter on the website, and stores it in the cloud (I use a simple Googlesheet). This is not difficult to do with the rvest and googlesheet4 packages. There was only one complication: The gym’s website is dynamically generated via Javascript, which meant downloading only the site the traditional way returns only an empty HTML-skeleton without the data I need. The webdriver package offers the solution. Its phantomjs() function mimicks a modern webbrowser that loads not only the site’s HTML but also any dynamically generated Javascript and allows R to load and store all its contents.
The code to load the website and extract the current occupancy data is shown below:
library(tidyverse)
library(webdriver)
library(rvest)pjs_instance <- run_phantomjs()
pjs_session <- Session$new(port = pjs_instance$port)# Scraping occupancy rate
#########################
url <- "http://www.lecube.ch/"
xpath <- "//*[@id='frequentation_jauge_current_raw']"pjs_session$go(url)
rendered_source <- pjs_session$getSource()
cube <- read_html(rendered_source)occ <- cube %>%
html_node(xpath=xpath) %>%
html_text() %>%
gsub("%","",.)time <- as.character.Date(Sys.time())cube_occ <- data.frame(time = time,
occ = as.numeric(occ))
The code also saves the current system time to be able to tell when a given value was scraped. The next part of the code (not shown) simply writes the data to a pre-prepared Googlesheet using the sheet_append() function in the googlesheets4 package.
As a final step, I used the taskscheduleR package to create a schedule on a Windows desktop machine to run this script every 30 minutes.
And then I waited…
Step 2: Forecasting
After around two weeks, I felt I had enough data to start playing around. Of course, two weeks of data are not enough to allow the computer to really learn the difference between a weekday and a Saturday or Sunday, but it should be enough for the algorithm to pick up the main dynamics in the data. It did turn out that there were some missing values, likely because the scraper failed or the data could not be stored (the log files were uninformative). I chose to linearly interpolate these missing values. Here’s how the interpolated data looked like — in an unpolished graph showing only the first week’s worth of data:

The data did indeed show a nice degree of regularity. Predictably, there are times when the gym is completely empty (at night), times when it is relatively calm (before and just after lunchtime) and times when it is very busy (the evenings).
Time to fire up the forecasting functions. I’ve used the forecast package before and liked it a lot, and it was therefore a natural way to start.
When it comes to algorithms, there are quite a number of options to choose from: There are very basic algorithms like the average method (the forecast is simply the average of the previous values) or the drift method (the average change, or trend, in the observed data is simply projected into the future), but also sophisticated methods like decomposition methods or methods based on time-series econometrics models (ARIMA).
Normally, one would try out several of them, also in different configurations, and compare their performances using a train-test splitted dataset.
For the first run, I wanted something flexible and quick, so I chose a neural network — specifically a feed-forward network with a single hidden layer that uses lagged values of the data as its inputs, which is implemented via the nnetar() function in the forecast package. A big advantage of this function (as with many others in the forecast package) is that it automatically selects optimal numbers of lagged values, which makes it quick to use.
The estimation and subsequent forecast are done in just a few lines of code:
fit <- nnetar(cubedata$occ_inter)
fcast <- forecast(fit,h=72)
autoplot(fcast)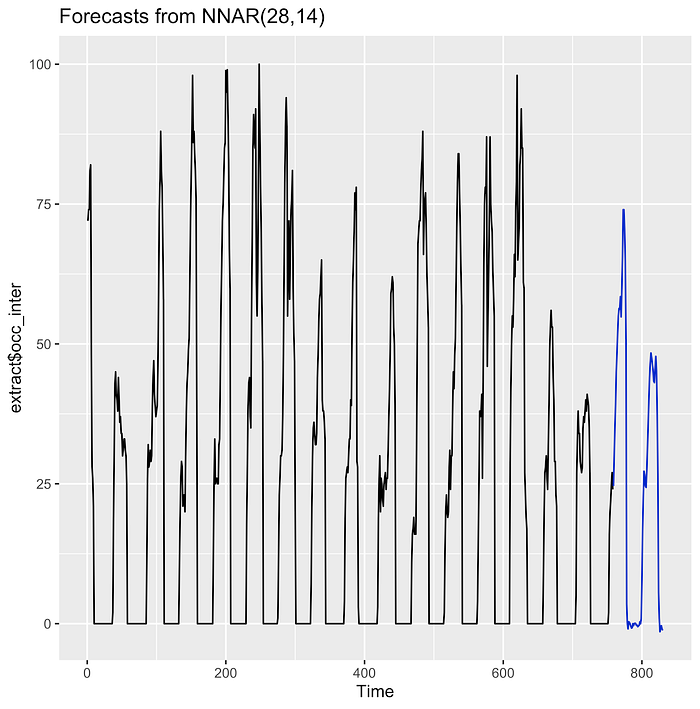
I set the horizon to 72 half-hours, i.e. 36 real hours. The result, shown in the graph to the left, is far from implausible.
Obviously, the forecast has to be taken with a few grains of salt — again, there are not enough data for the model to really learn the finer trends and seasonalities — but it seems the neural network was successful at picking up the main dynamics.
The graphical output is not very visually appealing, so the third and last step was to get everything into a more polished form.
Step 3: Deploy via a Shiny-dashboard
I could have simply polished the graph a bit, but I wanted to have this forecasting function in a form that I could also use when I don’t have a computer with R installed on it available — i.e. on my phone or tablet. A Shiny dashboard is a great option here, because it can be used to retrieve the stored data and run the forecast, and it can be styled so the result looks neat and, well, shiny. Plus, I can add a function to interactively set the forecast horizon to a value I want. Once the dashboard is deployed to a server (I use shinyapps.io), I can also always call the dashboard via my phone.
After some further data mangling plus creating my own custom theme for the dashboard (not shown because going over the code would be tedious; everything is deposited on my GitHub profile), the dashboard was then ready to go.
Next steps: As it is now, a new forecast model is estimated each time the dashboard is called, which means the selected model and thus the results vary over time. As soon as I have data for several more weeks (or even months) and there’s a good chance that the algorithm can pick up differences between weekdays and weekends, I will do a proper model selection based on a train-test split of the data.
